BLOB and the database
Today’s note I’d like to dedicate the topic of storing files with CoreData. Most of the databases available for iOS allow us to specify fields of BLOBs type. As all of You know it is not recommended to store within database itself due to query performance. For real numbers check out Internal Versus External BLOBs in SQLite article. When it comes to CoreData - BLOBs available as well. CoreData has extra options for attribute description and of them is Store in External Record File.
For full set of supported persisten store features check CoreData Programming Guide.
By checking this feature we say “Ok, CoreData, I’d like to keep those BLOBs in a separate file”. Starting from this point all required bookkeeping will be done automatically for You and no changes to code should be applied! Files stored either internally or externally due to Persistent Store logic without any effort. Unfortunately, sometime we do need to have some access to those files due number of reasons. And obviously framework doesn’t allow us to do so via public API. Ok, what next? We need to implement the file management on our own.
The filename
It means to implement save, delete and so on behind the scene. There are few ways to do so:
- Mimic Store in External Record File option and perform saves and deletes at appropriate moments within NSManagedObject. Active model.
- Make our model passive and store only related attributes. Files management performed outside of the object.
For both cases we need to have at least filename. And here we come to the main point of this article: filename should be unique, readonly, not related to the primary key or any attribute that handled externally. With no exceptions. Some explanation of every item:
- Unique - to prevent possible conflicts on the disk level. It simplifies management of the files.
- Readonly - Imagine next scheme of database
Post<->Attachment. At the moment of post editing user can add and delete attachments with no limits.readwriteallow to reuse the same Attachment object and some of the developers will accept this approach, whilereadonlyforces to delete previous object and create a new one from scratch. Second approach less error-prone, since every file linked with a separate object, no way to corrupt data. - Not related to the primary key - in the beginning I was planning to reuse
objectIDas it is already unique. However,NSManagedObject.objectIDs before save and after are not equal (see temporaryID) and we need to handle that change. Extra complexity, agree? So I decided to use my custom PK - it won’t be changed at all. The issue I faced with this approach is quite rare but worth to mention it here. In a single moment of time I had next set of objects:
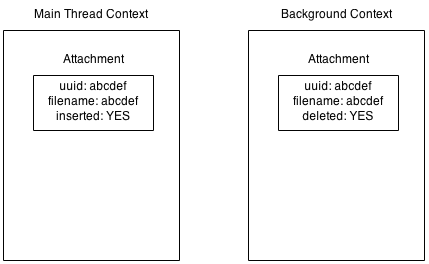
As You can see the same attachment presented in two NSManagedObjectContexts.
How that happened:
Attachmentwas fetched on both contexts- Main context deletes
Attachment,save:performed. Changes propagated to background context via notification but no save executed - Later the same object inserted into main thread by import from network
- At some point
save:received by background context -[NSManagedObject prepareForDeletion]invoked on already deletedAttachmentfrom background context- Since both deleted and inserted
Attachments have the same filename - file of insertedAttachmentremoved by deleted.
Weird, hah?
Some code
All You need is to declare managed object class as:
1 2 3 4 5 6 7 8 | |
While .m looks like that:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Some short description of code above: public interface allow client code to read filename but not modify it. The only place of modification is insert, which is handled in -awakeFromInsert.
Summary
Declaring Your objects as immutable makes Your code even more simple and elegant, since there is no place for possible conflicts, rewrites and data corruption anymore. Less cases to handle - less code. Less code - less errors, easier to maintain and update.
This is it for today, thanks for reading :)